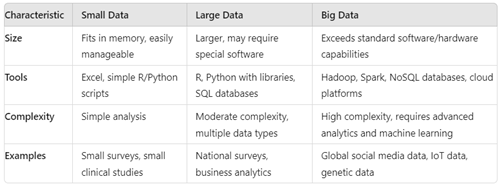
The terms “small,” “large,” and “big data” refer to the scale and complexity of datasets in different contexts.
Small data refers to datasets that are small enough to be easily processed and analyzed using simple tools or basic statistical methods. These datasets typically fit into the memory of a standard computer and can be managed with software like Microsoft Excel or basic R/Python scripts. For example, customer feedback surveys, small clinical trial results, or datasets with a few hundred rows and columns.
Large data involves more extensive datasets that require more sophisticated tools and techniques to process and analyse. Excel has 1,048,576 rows and 16,384 columns that may be considered a large data These datasets may not fit into a single computer’s memory but can be managed with more advanced software and statistical techniques. For example, national health surveys, social media data for a single company over a few years, or financial transactions records.
Big data refers to extremely large and complex datasets that exceed the processing capabilities of traditional data management tools. Any data in terabytes can be considered a big data. Big data is characterized by its Volume (large amounts of data), Velocity (rapid data generation), Variety (different types of data), and Veracity (uncertainty of data quality). Advanced technologies like Hadoop, Spark, and cloud computing resources are often required to handle big data. Examples would be Global social media data analysis, internet of things (IoT) sensor data, genome sequencing data, and large-scale e-commerce transaction data.